本日は、S3からファイルを読み込む方法とアップロードの方法を実践します。構築するシステムは以下のようなシステムになります。
- S3にファイルがアップロードされたら自動でLambdaを起動される
- Lambdaにて作成されたファイルを読み込んでデータをを加工
- 加工が終わったら、そのままS3にアップロードするようLambdaを設定
データ加工については以下の内容ですが、以下のように月の売り上げのエクセルファイルから 担当者の売り上げの平均値を別のエクセルに出すというものにします。
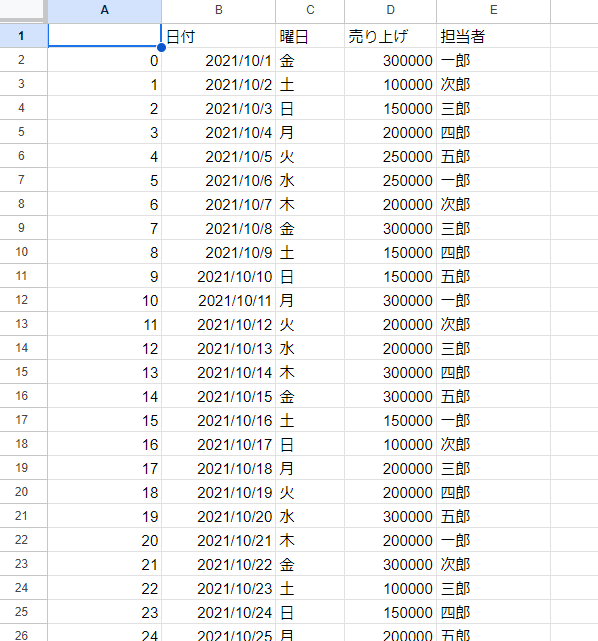
ライブラリはPandasを使用し、列の抽出、担当者のグループ化、平均値の出力の処理を行っています。 月の売り上げのエクセルの中身は以下のようになっております。見切れていますが31日まであります。
まずは、今回必要なリソースについては以下になります。
- 分析用のファイルを配置するS3バケットのフォルダ
- データ分析と結果を出力するLambda
- 分析結果の出力先のS3バケットのフォルダ
というわけで目次(作業)は以下の通りです。
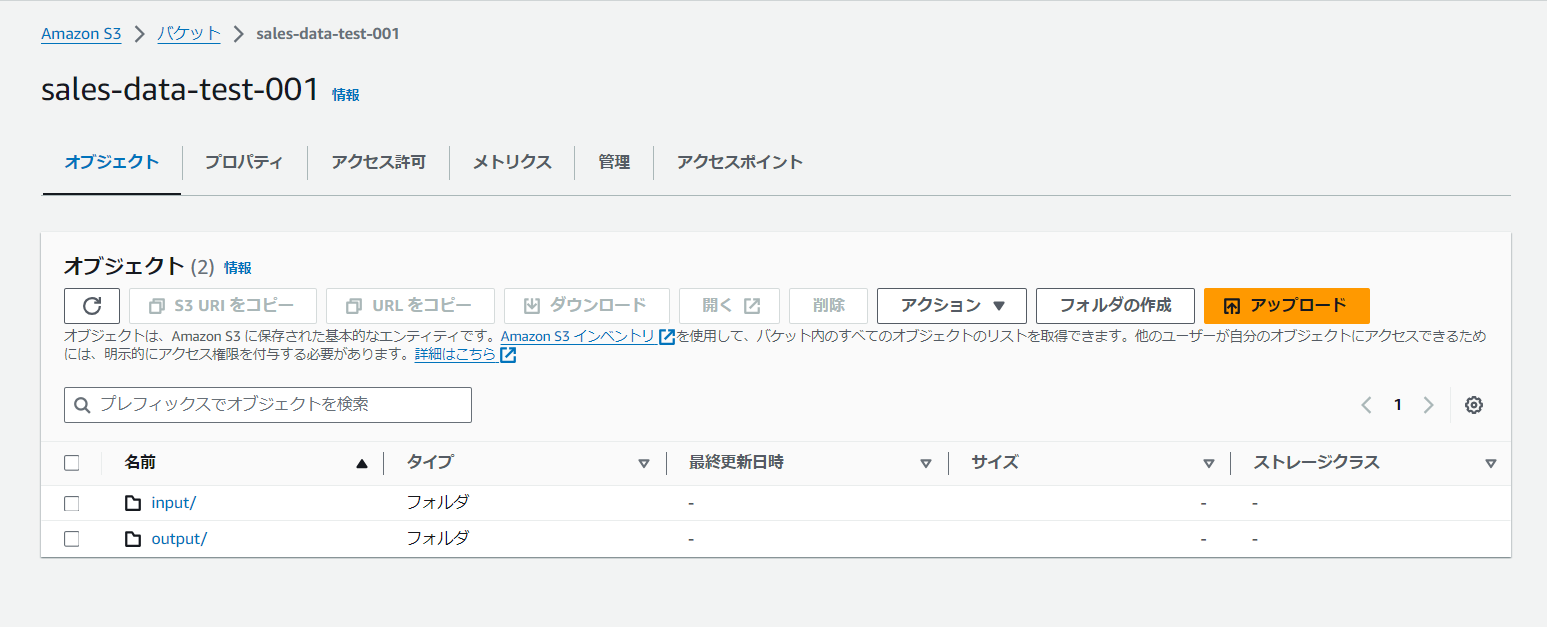
ファイルを配置・出力するS3バケットの作成
まずは、入力用と出力用のS3バケットです。今回は同じS3バケットで、入出力を行っていきます。 ここでは特に変わった作業はありません。S3バケットをデフォルト設定で作成して、バケット内に分析対象のフォルダをアップロードする「input」フォルダとLambdaから出力結果のファイルがアップロードされる「output」フォルダを作成しました。バケット名は「sales-data-test-001」としております。
inputフォルダにエクセルを配置すると自動でLambdaが起動し、outputフォルダに結果のファイルが格納されます。
Lambdaの作成
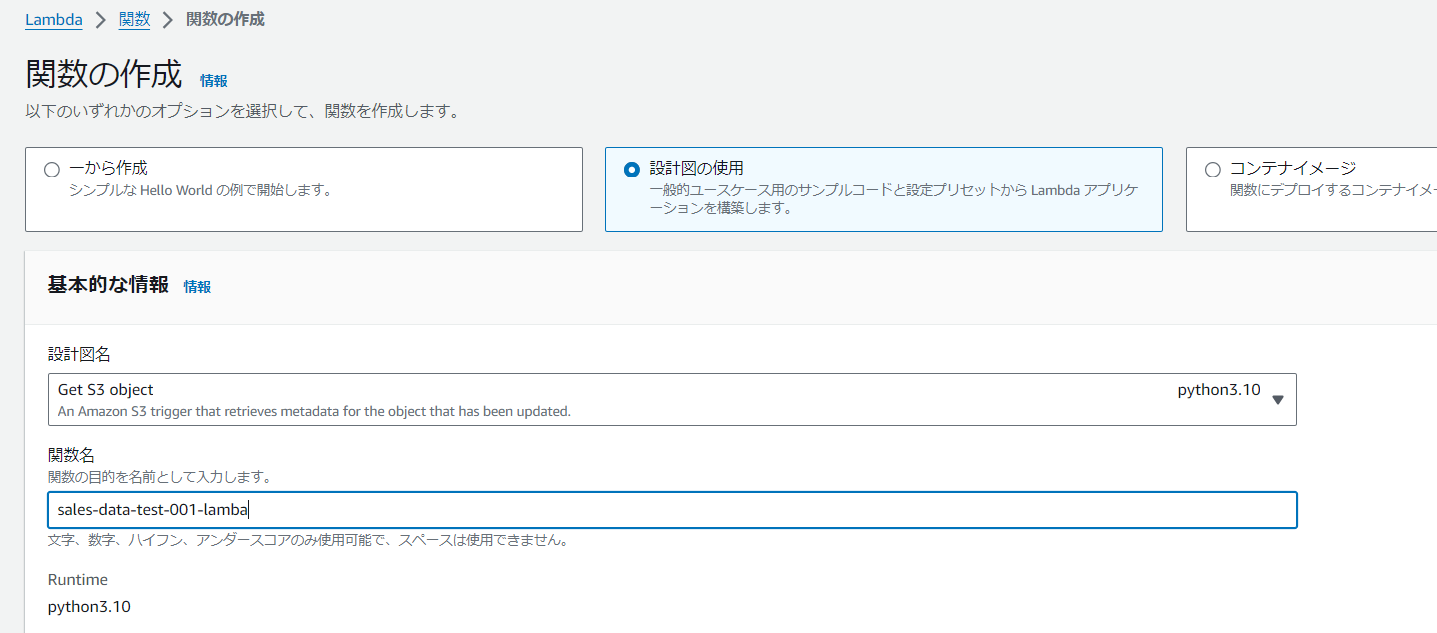
今回の仕組みではLambdaはS3のinputフォルダにファイルを置かれると自動でLambdaが起動されるようにします。 AWSにログインしてLambdaのコンソール画面に移動しLambdaの作成のボタンを押すと以下の画面が現れます。 Lambdaの便利機能ですが、以下の画面のように「設計図の使用」>「Get S3 Object」を選択すると、S3の操作をトリガーとする用の画面になってくれます。
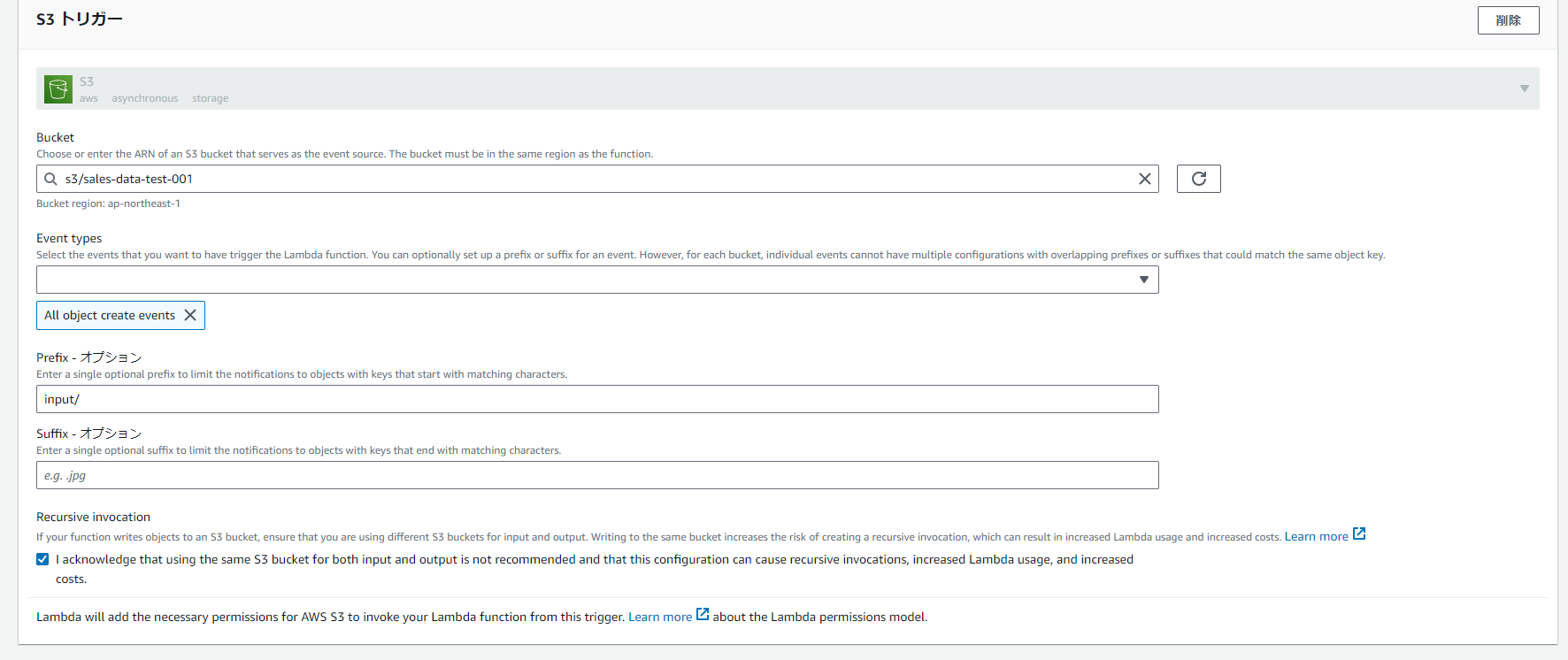
画面を下にスクロールすると以下のような画面があります。ここでは、S3のどの操作をトリガーとするか設定が可能です。今回は分析対象のファイルS3バケットの「input」フォルダを対象にしております。
ここでのパラメータ設定は以下です。
Bucket:sales-data-test-001
Event types:All object create events(ファイルが作成された操作の種類を意味します。もちろんこのイベント名にはアップロードも作成にはいります。)
prefix:input/
※prefixは頭に付ける文字列、sufixはしっぽに付ける文字列です。今回は「input/ファイル名」になるので、「input」と設定してます。
これで作成してLambdaの画面を見てます。ちゃんとトリガー設定されてますね。
Lambdaのpythonコーディング
ここが一番時間がかかります。
以下のようにひとつずつやっていきます。以下を見て何言ってるか分からんと言う人でもピクチャを見せながら説明しますので、現時点で分からなくても大丈夫だと思います。
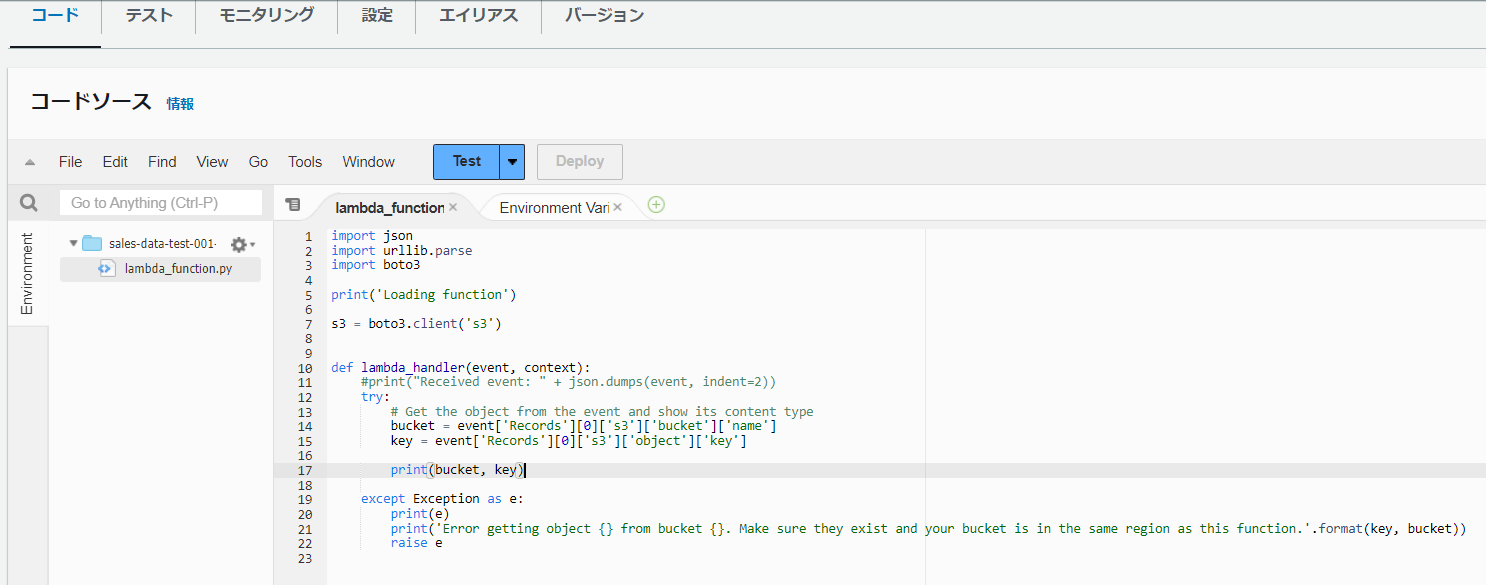
①バケット名、キー名(フォルダとファイル名)を取得できるか確認(バケット名、キー名をprint()で出力します。)
②S3のエクセルを読み込んでPandasのデータフレーム(df)に取り込めるか確認(dfをprint()で出力します。)
③データ加工して結果を確認。(結果を新しいデータフレームdf_newに入れてdf_newをprint()で出力します)
④df_newをエクセルファイルに変換して、S3バケットに「output」フォルダに出力。
①バケット名、キー名(フォルダとファイル名)を取得できるか確認(バケット名、キー名をprint()で出力します。)
まずはS3のアップロードをトリガーにした時にLambdaにどんな情報が来るのかを確認します。
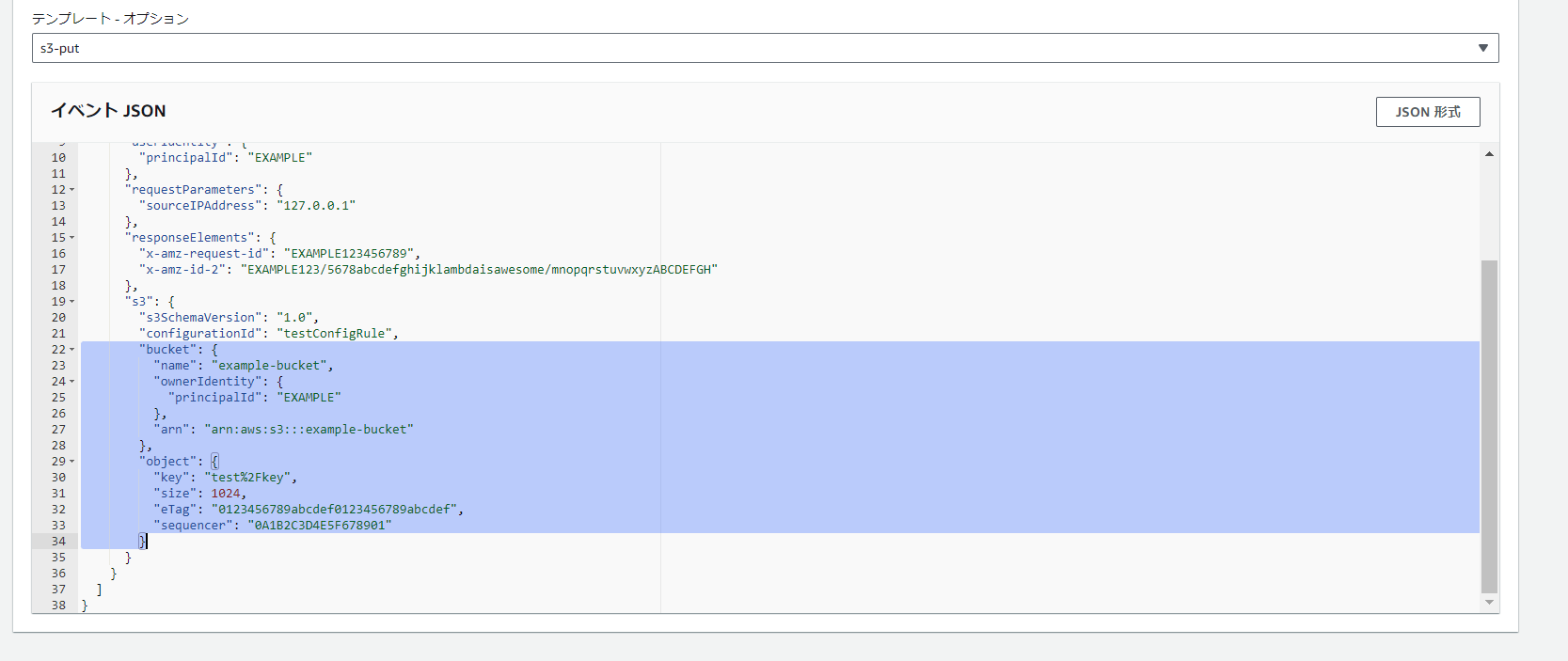
Lambdaの画面で「テスト」タブを選択しテンプレートオプションで「s3-put」を選択します。そうすると「こんな風に送られてきますよ」というのが見れます。 確認すると[‘Record’]の中の「0」番目の[‘s3’]の中の[‘bucket’]の中の[‘name’]にバケット名が入っているので「event[‘Record’][0][‘s3’][‘bucket’][‘name’]」で取得できますね。キー名も同じように取得できます。
コードは以下のようになります。14,15行目でバケット名とキー名を取得し、17行名で出力します。
実際にファイル(SalesData.xlsx)をアップロードしてCloudwatchで出力結果を確認。ちゃんと二つとも出力されてますね。
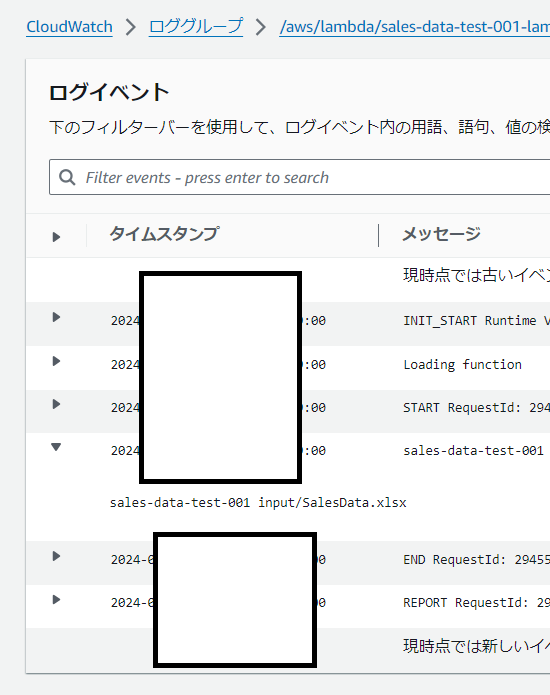
②S3のエクセルを読み込んでPandasのデータフレーム(df)に取り込めるか確認(dfをprint()で出力します。)
まずは、pandasとexcelを扱うため、pandasとopenpyxlのレイヤーを設定します。レイヤー設定は画面上の「レイヤーの追加」から設定できます。 python3.10なので以下から探して追加しました。
https://github.com/keithrozario/Klayers/tree/master/deployments/python3.10 
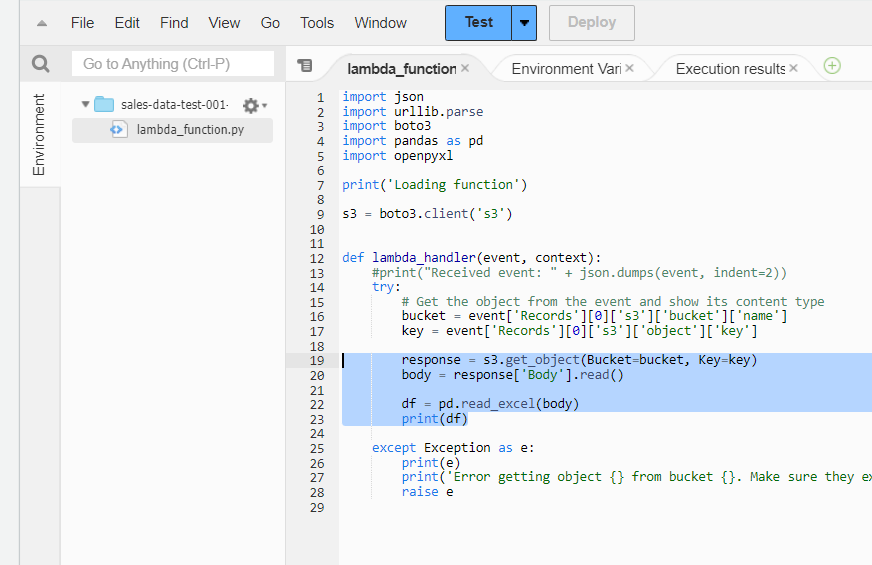
18,19行目でS3のファイルを読み込んで「body」に格納して、22行目でエクセルファイルをデータフレーム(df)に格納します。23行目は出力です。 4,5行目でpandasとopenpyxlをインポートするのを忘れないでください。
Cloudwatchの出力結果
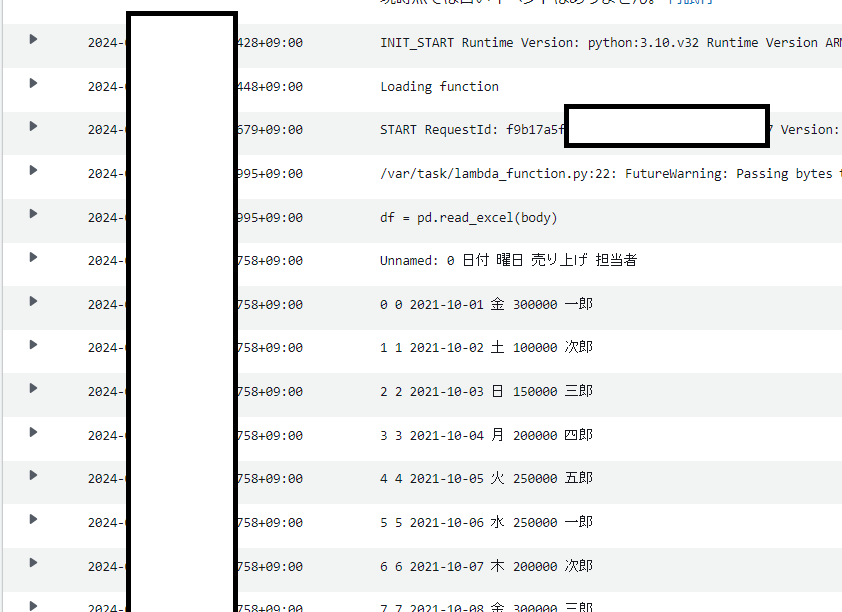
③データ加工して結果を確認。(結果を新しいデータフレームdf_newに入れてdf_newをprint()で出力します)
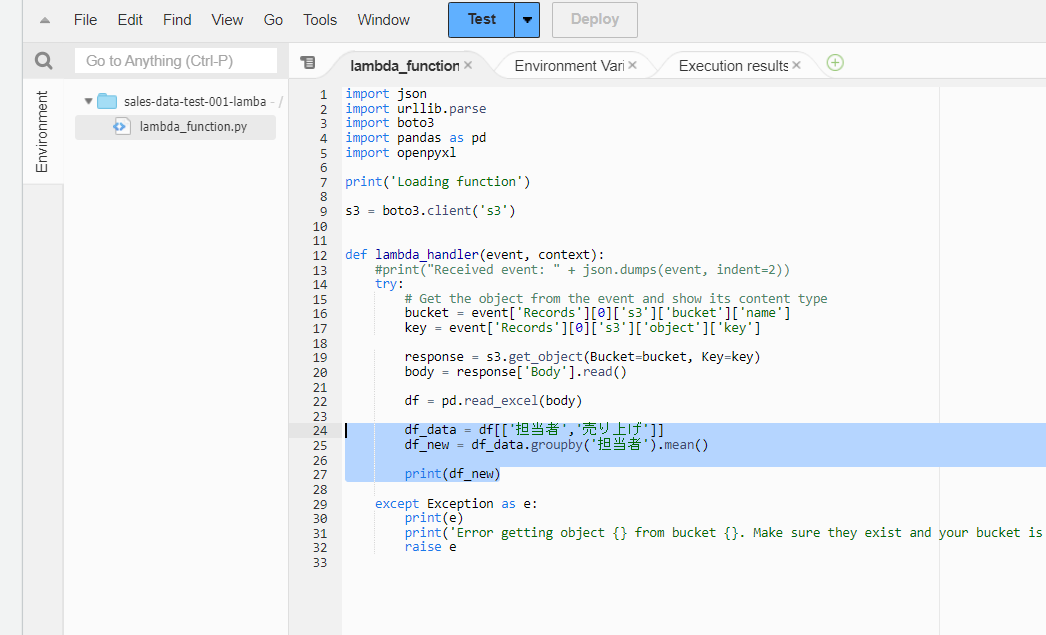
24行目で担当者と売り上げの列を抽出し、25行目で担当者でグループ化して、平均値(mean)を出しています。
Cloudwatchの出力結果
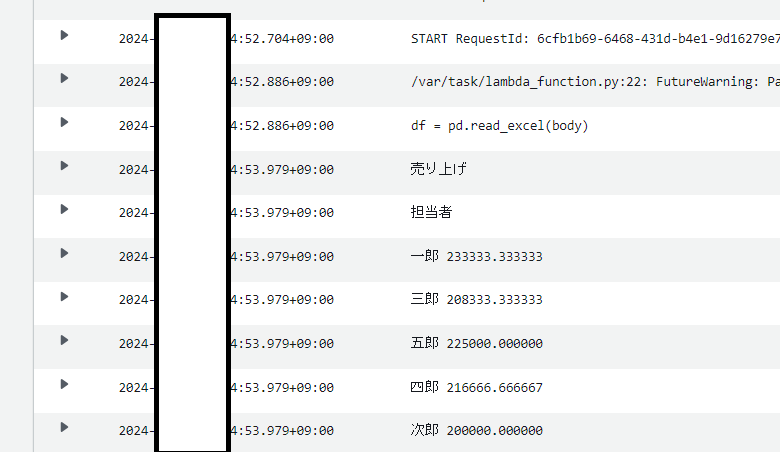
④df_newをエクセルファイルに変換して、S3バケットに「output」フォルダに出力。
27行目で「df_new」のデータをエクセルに変換し、「/tmp」フォルダに「new_data.xlsx」として格納しています。このtempのフォルダですが、Lambdaの中にはtempフォルダがあり、一時的にファイルを格納できるようになっています。
28行目でついに、new_data.xlsxをS3バケット「sales-data-test-001」の「output」フォルダに出力します。
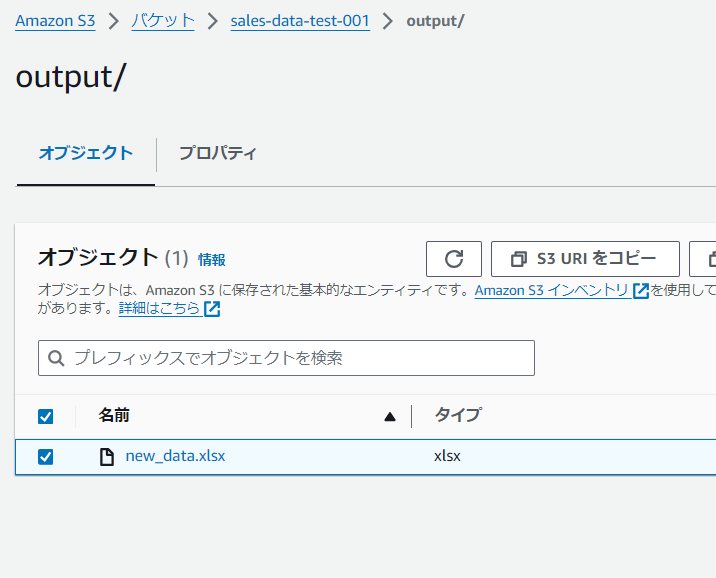
実行結果
ではいよいよ実行します。まずは、S3のinputフォルダにファイルをアップロードします。。。
数秒待ったらoutputフォルダに結果が出力されました。
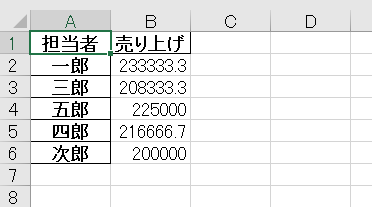
本記事は以上になります。最後までご覧いただきありがとうございました。
AWS Certified Data Analytics – Specialty (DAS)に1か月で合格したので勉強内容を話します。
![]()